What is Spark Architecture ? Define in brief ?
Last Updated April 18, 2025
Apache Spark is a distributed data processing engine designed for speed, scalability, and ease of use. It follows a master-slave architecture composed of the following components:
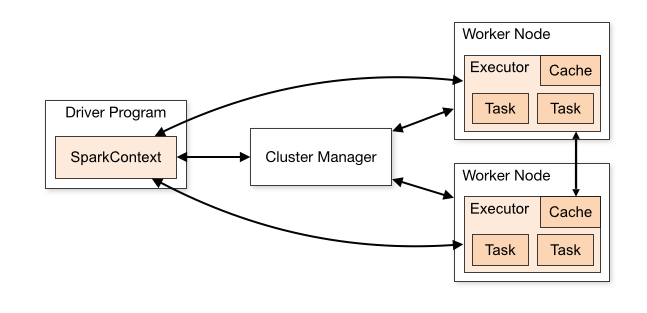
Let's understand each step one by one
The Spark Driver
It acts as a master node which contains the SparkContext (the entrypoint of the spark application) . It is responsible for translating user code into Directed Acyclic Graph (DAG) and distributing tasks to executors and monitoring their progress.
Cluster Manager
The cluster manager is responsible for allocating resources and managing the cluster on which the Spark application runs. Spark supports various cluster managers like Apache Mesos, Hadoop YARN, and standalone cluster manager.
Executors
Executors are worker processes that run on the cluster nodes and are responsible for executing the tasks assigned by the driver program. Each executor is allocated by the cluster manager and works independently to carry out the computations. Executors perform the actual data processing by executing tasks, storing intermediate data in memory or disk for caching and reuse, and sending the results or status updates back to the driver. They play a crucial role in distributed execution and contribute significantly to Spark's high performance and scalability.